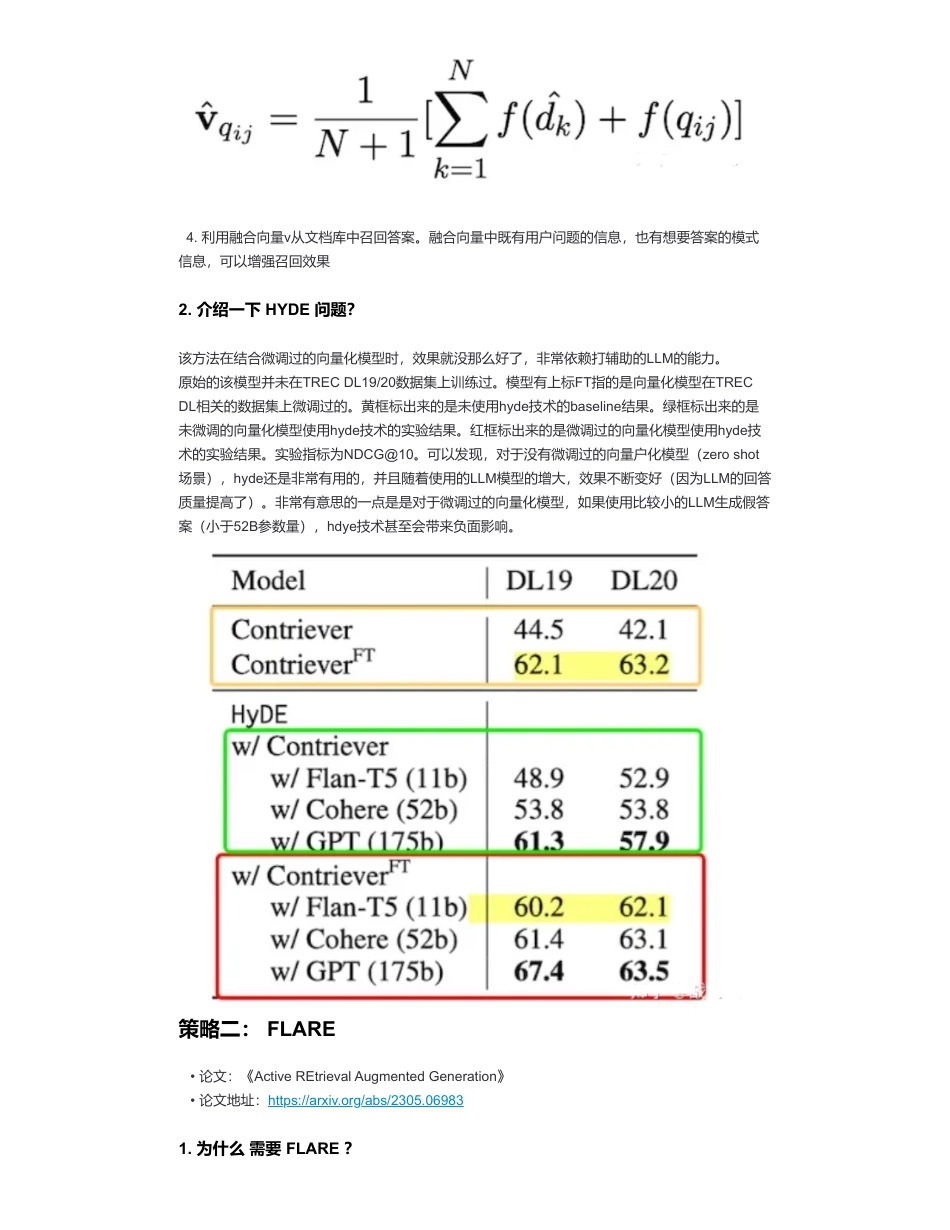
大模型外挂知识库优化——如何利用大模型辅助召回?来自:AiGC面试宝典宁静致远2024年03月19日22:30一、为什么需要使用大模型辅助召回?我们可以通过向量召回的方式从文档库里召回和用户问题相关的文档片段,同时输入到LLM中,增强模型回答质量。常用的方式直接用用户的问题进行文档召回。但是很多时候,用户的问题是十分口语化的,描述的也比较模糊,这样会影响向量召回的质量,进而影响模型回答效果。策略一:HYDE1.介绍一下HYDE思路?•大模型外挂知识库优化——如何利用大模型辅助召回?•一、为什么需要使用大模型辅助召回?•策略一:HYDE•1.介绍一下HYDE思路?•2.介绍一下HYDE问题?•策略二:FLARE•1.为什么需要FLARE?•2.FLARE有哪些召回策略?•2.1策略1•2.1.1策略1思路?•2.1.2策略1缺陷?•2.2策略2•2.2.1策略2思路?•致谢•论文:《PreciseZero-ShotDenseRetrievalwithoutRelevanceLabels》•论文地址:https://arxiv.org/pdf/2212.10496.pdf1.用LLM根据用户query生成k个“假答案”。(大模型生成答案采用sample模式,保证生成的k个答案不一样。此时的回答内容很可能是存在知识性错误,因为如果能回答正确,那就不需要召回补充额外知识了对吧。不过不要紧,我们知识想通过大模型去理解用户的问题,生成一些“看起来”还不错的假答案)2.利用向量化模型,将生成的k的假答案和用户的query变成向量;3.将k+1个向量取平均:其中dk为第k个生成的答案,q为用户问题,f为向量化操作。扫码加查看更多4.利用融合向量v从文档库中召回答案。融合向量中既有用户问题的信息,也有想要答案的模式信息,可以增强召回效果2.介绍一下HYDE问题?该方法在结合微调过的向量化模型时,效果就没那么好了,非常依赖打辅助的LLM的能力。原始的该模型并未在TRECDL19/20数据集上训练过。模型有上标FT指的是向量化模型在TRECDL相关的数据集上微调过的。黄框标出来的是未使用hyde技术的baseline结果。绿框标出来的是未微调的向量化模型使用hyde技术的实验结果。红框标出来的是微调过的向量化模型使用hyde技术的实验结果。实验指标为NDCG@10。可以发现,对于没有微调过的向量户化模型(zeroshot场景),hyde还是非常有用的,并且随着使用的LLM模型的增大,效果不断变好(因为LLM的回答质量提高了)。非常有意思的一点是是对于微调过的向量化模型,如果使用比较小的LLM生成假答案(小于52B参数量),hdye技术甚至会带来负面影响。策略二:FLARE1.为什么需要FLARE?•论文:《ActiveREtrievalAugmentedGeneration》•论文地址:https://arxiv.org/abs/2305.06983对于大模型外挂知识库,大家通常的做法是根据用户query一次召回文档片段,让模型生成答案。只进行一次文档召回在长文本生成的场景下效果往往不好,生成的文本过长,更有可能扩展出和query相关性较弱的内容,如果模型没有这部分知识,容易产生模型幻觉问题。一种解决思路是随着文本生成,多次从向量库中召回内容。2.FLARE有哪些召回策略?已有的多次召回方案比较被动,召回文档的目的是为了得到模型不知道的信息,a、b策略并不能保证不需要召回的时候不召回,需要召回的时候触发召回。c.方案需要设计特定的prompt工程,限制了其通用性。作者在本文里提出了两种更主动的多次召回策略,让模型自己决定啥时候触发召回操作。2.1策略12.1.1策略1思路?通过设计prompt以及提供示例的方式,让模型知道当遇到需要查询知识的时候,提出问题,并按照格式输出,和toolformer的模式类似。下图展示了生成拜登相关答案时,触发多次召回的例子,分别面对拜登在哪上学和获得了什么学位的知识点上进行了主动召回标识的生成。1.每生成固定的n个token就召回一次;2.每生成一个完整的句子就召回一次;3.用户query一步步分解为子问题,需要解答当前子问题时候,就召回一次1.提出问题的格式为[Serch(“模型自动提出的问题”)](称其为主动召回标识)。利用模型生成的问题去召回答案。2.召回出答案后,将答案放到用户query的前边,然后去掉主动召回标识之后,继续生成。3.当下一次生成主动召回标识之后,将上一次召回出来的内容从prompt中去掉。2.1.2策略1...










发表评论取消回复