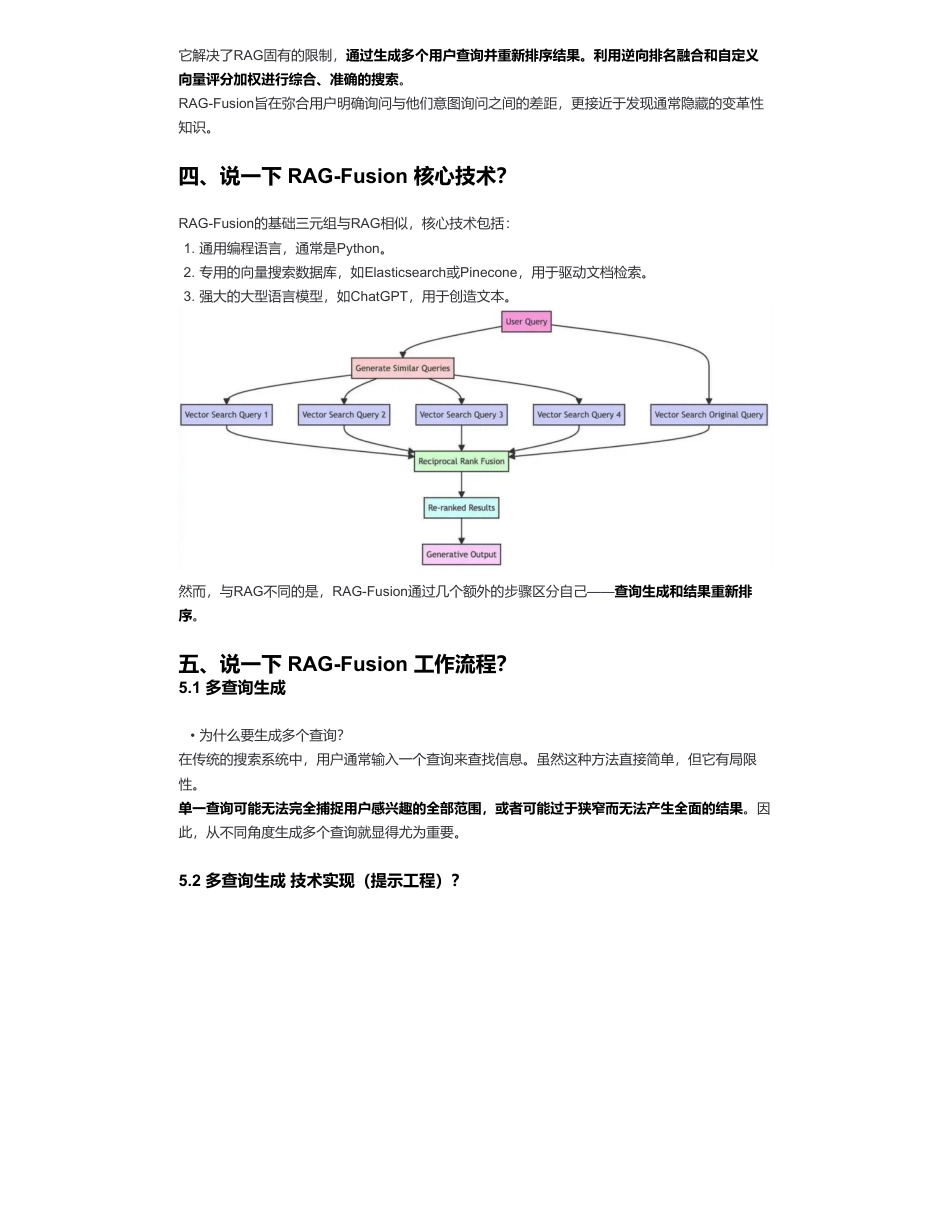
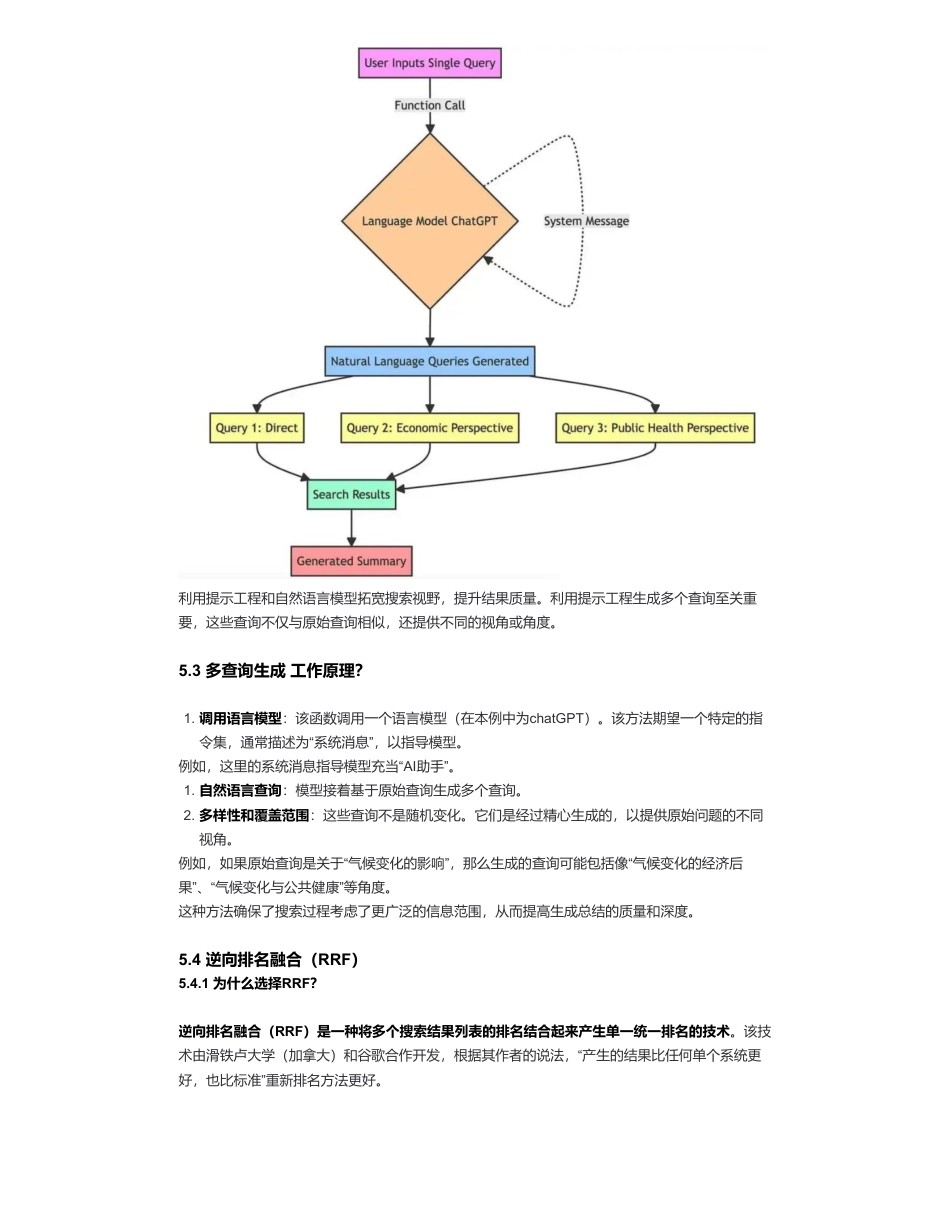
大模型(LLMs)RAG优化策略——RAG-Fusion篇来自:AiGC面试宝典宁静致远2024年03月19日22:30一、RAG有哪些优点?二、RAG存在哪些局限性?三、为什么需要RAG-Fusion?•大模型(LLMs)RAG优化策略——RAG-Fusion篇•一、RAG有哪些优点?•二、RAG存在哪些局限性?•三、为什么需要RAG-Fusion?•四、说一下RAG-Fusion核心技术?•五、说一下RAG-Fusion工作流程?•5.1多查询生成•5.2多查询生成技术实现(提示工程)?•5.3多查询生成工作原理?•5.4逆向排名融合(RRF)•5.4.1为什么选择RRF?•5.4.2RRF技术实现?•5.4.3生成性输出用户意图保留•5.4.4生成性输出用户意图保留技术实现•六、RAG-Fusion的优势和不足•6.1RAG-Fusion优势•6.2RAG-Fusion挑战•致谢1.向量搜索融合:RAG通过将向量搜索功能与生成模型相结合,引入了一种新颖的范式。这种融合使大型语言模型(LLM)能够生成更丰富、更具上下文意识的输出。2.减少幻觉现象:RAG显著降低了LLM产生幻觉的倾向,使生成的文本更加基于数据。3.个人和专业效用:从个人应用(如浏览笔记)到更专业的集成,RAG在提高生产力和内容质量方面展示了其多功能性,同时基于可信的数据来源。1.当前搜索技术的限制:RAG受到限制的方面与我们的检索式基于词汇和向量的搜索技术相同。2.人类搜索效率低下:人类在向搜索系统输入他们想要的内容时并不擅长,如打字错误、含糊的查询或词汇有限,这常常导致错过那些超出显而易见的顶部搜索结果的大量信息。虽然RAG有所帮助,但它并没有完全解决这个问题。3.搜索的过度简化:我们普遍的搜索范式是将查询线性映射到答案,缺乏理解人类查询的多维性。这种线性模型通常无法捕捉更复杂用户查询的细微差别和上下文,导致结果相关性较低。扫码加查看更多它解决了RAG固有的限制,通过生成多个用户查询并重新排序结果。利用逆向排名融合和自定义向量评分加权进行综合、准确的搜索。RAG-Fusion旨在弥合用户明确询问与他们意图询问之间的差距,更接近于发现通常隐藏的变革性知识。四、说一下RAG-Fusion核心技术?RAG-Fusion的基础三元组与RAG相似,核心技术包括:然而,与RAG不同的是,RAG-Fusion通过几个额外的步骤区分自己——查询生成和结果重新排序。五、说一下RAG-Fusion工作流程?5.1多查询生成在传统的搜索系统中,用户通常输入一个查询来查找信息。虽然这种方法直接简单,但它有局限性。单一查询可能无法完全捕捉用户感兴趣的全部范围,或者可能过于狭窄而无法产生全面的结果。因此,从不同角度生成多个查询就显得尤为重要。5.2多查询生成技术实现(提示工程)?1.通用编程语言,通常是Python。2.专用的向量搜索数据库,如Elasticsearch或Pinecone,用于驱动文档检索。3.强大的大型语言模型,如ChatGPT,用于创造文本。•为什么要生成多个查询?利用提示工程和自然语言模型拓宽搜索视野,提升结果质量。利用提示工程生成多个查询至关重要,这些查询不仅与原始查询相似,还提供不同的视角或角度。5.3多查询生成工作原理?例如,这里的系统消息指导模型充当“AI助手”。例如,如果原始查询是关于“气候变化的影响”,那么生成的查询可能包括像“气候变化的经济后果”、“气候变化与公共健康”等角度。这种方法确保了搜索过程考虑了更广泛的信息范围,从而提高生成总结的质量和深度。5.4逆向排名融合(RRF)5.4.1为什么选择RRF?逆向排名融合(RRF)是一种将多个搜索结果列表的排名结合起来产生单一统一排名的技术。该技术由滑铁卢大学(加拿大)和谷歌合作开发,根据其作者的说法,“产生的结果比任何单个系统更好,也比标准”重新排名方法更好。1.调用语言模型:该函数调用一个语言模型(在本例中为chatGPT)。该方法期望一个特定的指令集,通常描述为“系统消息”,以指导模型。1.自然语言查询:模型接着基于原始查询生成多个查询。2.多样性和覆盖范围:这些查询不是随机变化。它们是经过精心生成的,以提供原始问题的不同视角。通过结合不同查询的排名,我们增加了最相关文档出现在最终列表顶部的机会。RRF特别有效,因为它不依赖于搜索引擎分配的绝对分数,而是依赖于相对排名,使其非常适合结合...









发表评论取消回复