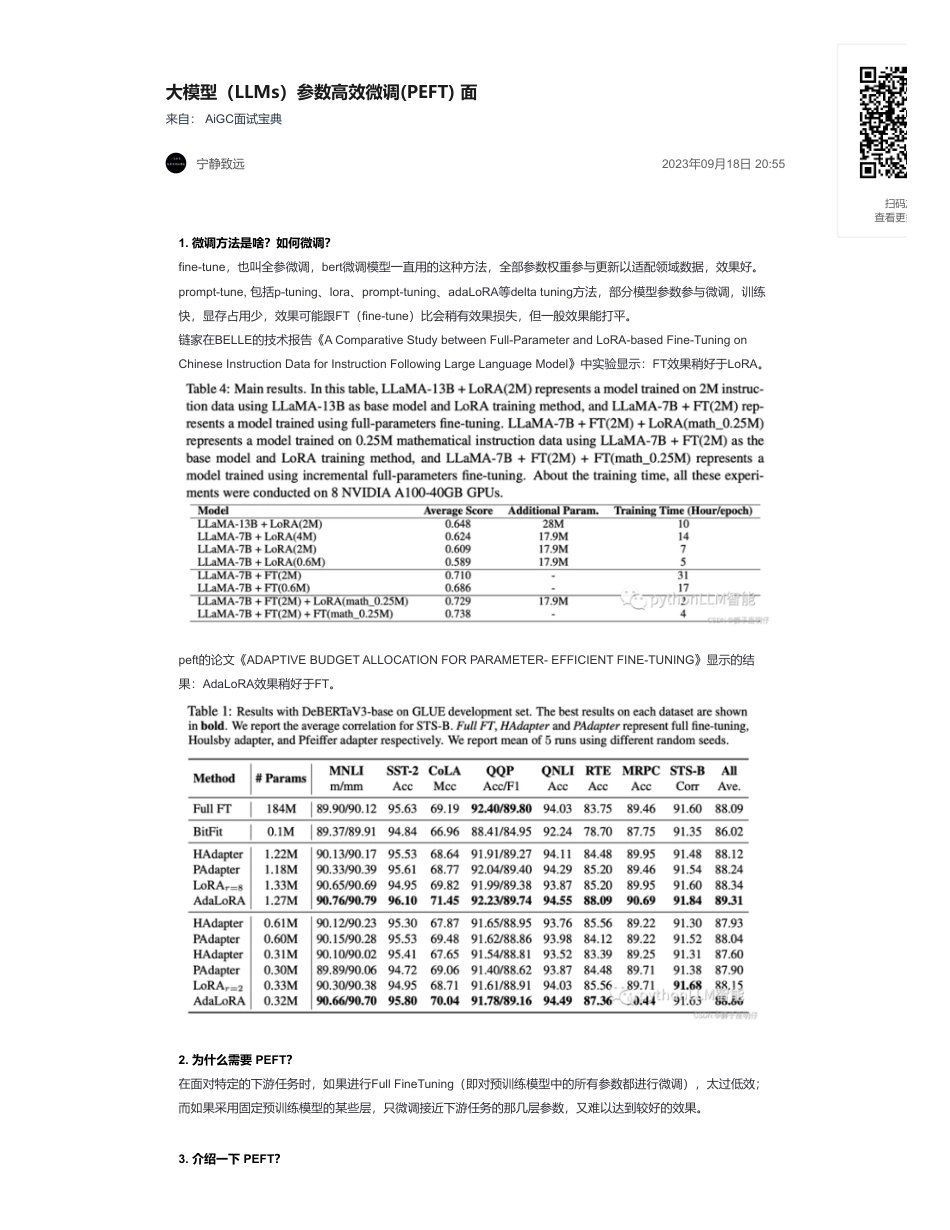
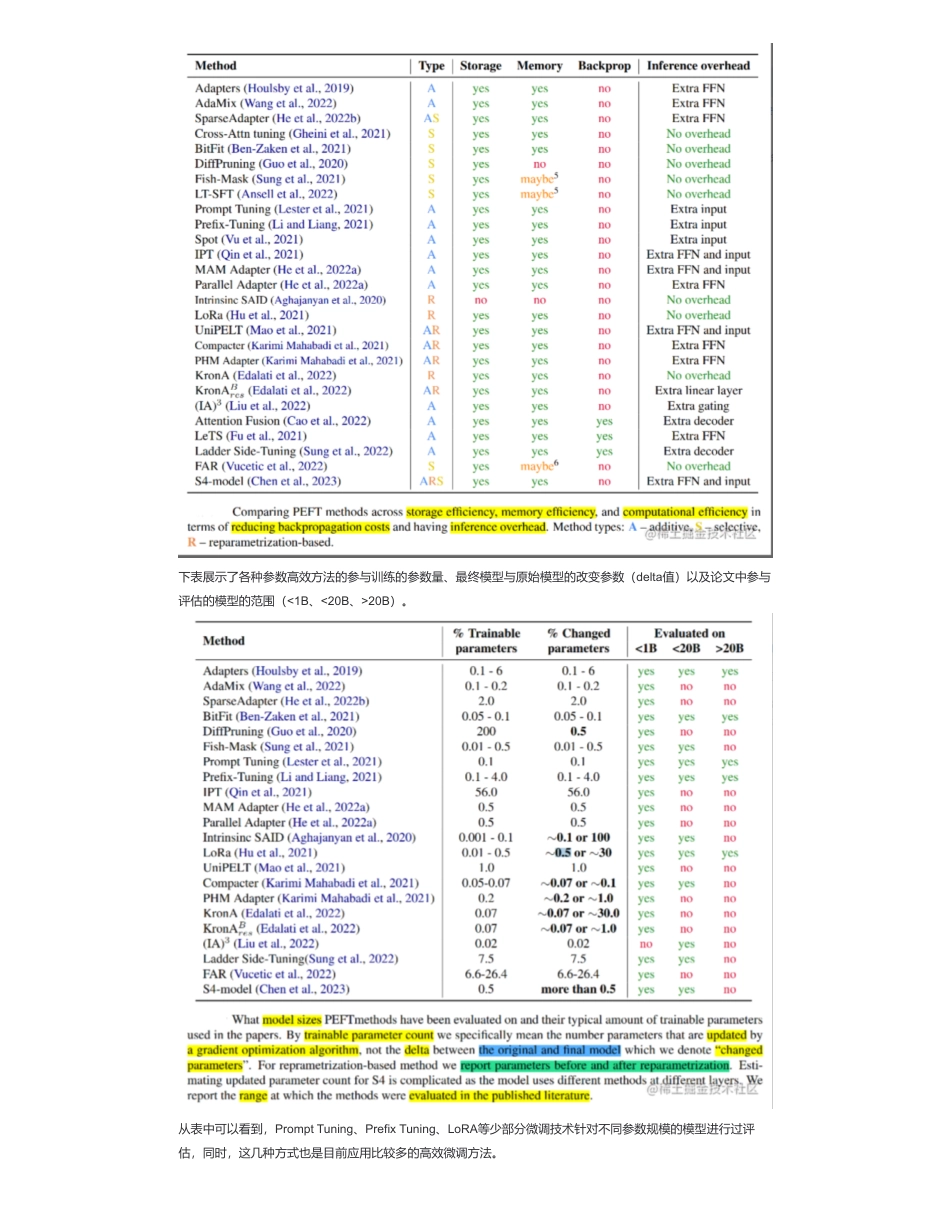
大模型(LLMs)参数高效微调(PEFT)面来自:AiGC面试宝典宁静致远2023年09月18日20:551.微调方法是啥?如何微调?fine-tune,也叫全参微调,bert微调模型一直用的这种方法,全部参数权重参与更新以适配领域数据,效果好。prompt-tune,包括p-tuning、lora、prompt-tuning、adaLoRA等deltatuning方法,部分模型参数参与微调,训练快,显存占用少,效果可能跟FT(fine-tune)比会稍有效果损失,但一般效果能打平。链家在BELLE的技术报告《AComparativeStudybetweenFull-ParameterandLoRA-basedFine-TuningonChineseInstructionDataforInstructionFollowingLargeLanguageModel》中实验显示:FT效果稍好于LoRA。peft的论文《ADAPTIVEBUDGETALLOCATIONFORPARAMETER-EFFICIENTFINE-TUNING》显示的结果:AdaLoRA效果稍好于FT。2.为什么需要PEFT?在面对特定的下游任务时,如果进行FullFineTuning(即对预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。3.介绍一下PEFT?扫码加查看更多PEFT技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。这样一来,即使计算资源受限,也可以利用预训练模型的知识来迅速适应新任务,实现高效的迁移学习。4.PEFT有什么优点?PEFT技术可以在提高模型效果的同时,大大缩短模型训练时间和计算成本,让更多人能够参与到深度学习研究中来。除此之外,FEFT可以缓解全量微调带来灾难性遗忘的问题。5.微调方法批处理大小模式GPU显存速度?微调方法批处理大小模式GPU显存速度6.Peft和全量微调区别?所谓的fune-tine只能改变风格,不能改变知识,是因为我们的fine-tune,像是LoRA本来就是低秩的,没办法对模型产生决定性的改变.要是全量微调,还是可以改变知识的.7.多种不同的高效微调方法对比像P-Tuningv2、LoRA等都是综合评估很不错的高效微调技术。如果显存资源有限可以考虑QLoRA;如果只是解决一些简单任务场景,可以考虑P-Tuning、PromptTuning也行。下表从参数高效方法类型、是否存储高效和内存高效、以及在减少反向传播成本和推理开销的计算高效五个维度比较了参数高效微调方法。LoRA(r=8)16FP1628GB8ex/sLoRA(r=8)8FP1624GB8ex/sLoRA(r=8)4FP1620GB8ex/sLoRA(r=8)4INT810GB8ex/sLoRA(r=8)4INT48GB8ex/sP-Tuning(p=16)4FP1620GB8ex/sP-Tuning(p=16)4INT816GB8ex/sP-Tuning(p=16)4INT412GB8ex/sFreeze(l=3)4FP1624GB8ex/sFreeze(l=3)4INT812GB8ex/s下表展示了各种参数高效方法的参与训练的参数量、最终模型与原始模型的改变参数(delta值)以及论文中参与评估的模型的范围(<1B、<20B、>20B)。从表中可以看到,PromptTuning、PrefixTuning、LoRA等少部分微调技术针对不同参数规模的模型进行过评估,同时,这几种方式也是目前应用比较多的高效微调方法。8.当前高效微调技术存在的一些问题当前的高效微调技术很难在类似方法之间进行直接比较并评估它们的真实性能,主要的原因如下所示:9.高效微调技术最佳实践针对以上存在的问题,研究高效微调技术时,建议按照最佳实践进行实施:10.PEFT存在问题?相比全参数微调,大部分的高效微调技术目前存在的两个问题:11.能不能总结一下各种参数高效微调方法?本文针对之前介绍的几种参数高效微调方法进行了简单的概述,主要有如下几类:并比较了不同的高效微调方法之间的差异;同时,还指出当前大多数高效微调方法存在的一些问题并给出了最佳实践。知识星球•参数计算口径不一致:参数计算可以分为三类:可训练参数的数量、微调模型与原始模型相比改变的参数的数量、微调模型和原始模型之间差异的等级。例如,DiffPruning更新0.5%的参数,但是实际参与训练的参数量是200%。这为比较带来了困难。尽管可训练的参数量是最可靠的存储高效指标,但是也不完美。Ladder-sideTuning使用一个单独的小网络,参数量高于LoRA或BitFit,但是因为反向传播不经过主网络,其消耗的内存反而更小。•缺乏模型大小的考虑:已有工作表明,大模型在微调中需要更新的参数量更小(无论...









发表评论取消回复