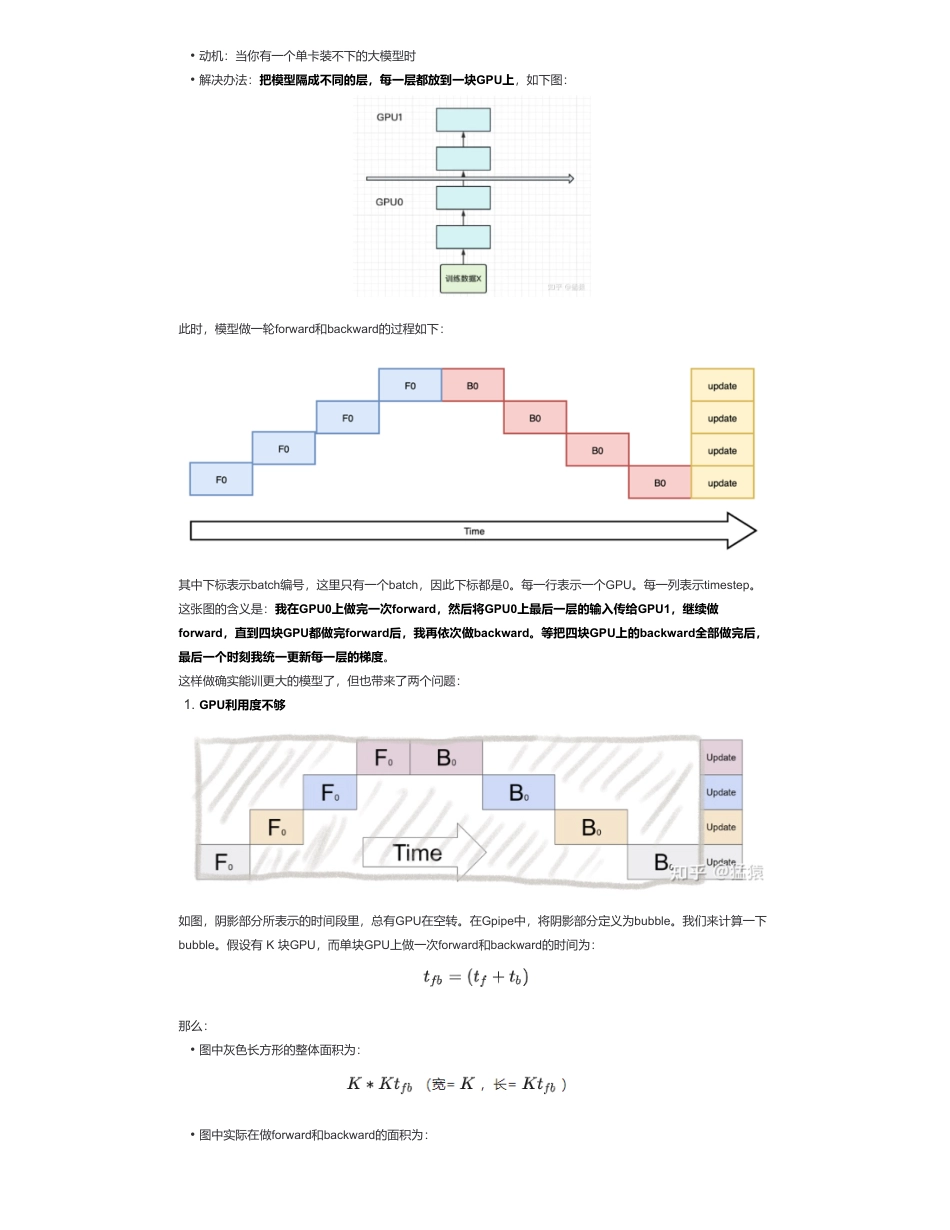
图解分布式训练(一)——流水线并行(PipelineParallelism)来自:AiGC面试宝典宁静致远2023年09月29日11:02为什么需要流水线并行(PipelineParallelism)?回顾ChatGPT的发展历程,我们可以总结出大语言模型(LLM)取得惊艳效果的要点(重要性从高到低排序):在大模型训练这个系列里,我们将一起探索学习几种经典的分布式并行范式,包括流水线并行(PipelineParallelism),数据并行(DataParallelism)和张量并行(TensorParallesim)。微软开源的分布式训练框DeepSpeed,融合了这三种并行范式,开发出3D并行的框架,实现了千亿级别模型参数的训练。本篇文章将探索流水线并行,经典的流水线并行范式有Google推出的Gpipe,和微软推出的PipeDream。两者的推出时间都在2019年左右,大体设计框架一致。主要差别为:在梯度更新上,Gpipe是同步的,PipeDream是异步的。异步方法更进一步降低了GPU的空转时间比。虽然PipeDream设计更精妙些,但是Gpipe因为其“够用”和浅显易懂,更受大众欢迎(torch的pp接口就基于Gpipe)。因此本文以Gpipe作为流水线并行的范例进行介绍。本文内容包括:一、流水线并行(PipelineParallelism)优化目标是什么?当你从单卡穷人变成多卡富翁时,你做分布式训练的总体目标是什么呢?(虽然手握一张A100怎么能是穷呢)这是目标,也是难点,难在于:二、图解流水线并行(PipelineParallelism)模型并行必要性?1.愿意烧钱,且接受“烧钱!=好模型”的现实2.高质量的训练语料3.高效的分布式训练框架和充沛优质的硬件资源4.算法的迭代创新1.优化目标2.模型并行3.流水线并行a.切分micro-batchb.Re-materialization(activecheckpoint)4.实验效果a.GPU数量VS模型大小b.GPU数量VS训练速度c.Gpipe下单GPU的时间消耗分析•能训练更大的模型。理想状况下,模型的大小和GPU的数量成线性关系。即GPU量提升x倍,模型大小也能提升x倍。•能更快地训练模型。理想状况下,训练的速度和GPU的数量成线性关系。即GPU量提升x倍,训练速度也能提升x倍。•训练更大的模型时,每块GPU里不仅要存模型参数,还要存中间结果(用来做Backward)。而更大的模型意味着需要更多的训练数据,进一步提高了中间结果的大小。加重了每块GPU的内存压力。我们将在下文详细分析这一点。(对应着GPU中的内存限制)•网络通讯开销。数据在卡之间进行传输,是需要通讯时间的。不做设计的话,这个通讯时间可能会抹平多卡本身带来的训练速度提升。(对应着GPU间的带宽限制)•明确这两个训练目标后,我们来看并行范式的设计者,是如何在现有硬件限制的条件下,完成这两个目标的。扫码加查看更多此时,模型做一轮forward和backward的过程如下:其中下标表示batch编号,这里只有一个batch,因此下标都是0。每一行表示一个GPU。每一列表示timestep。这张图的含义是:我在GPU0上做完一次forward,然后将GPU0上最后一层的输入传给GPU1,继续做forward,直到四块GPU都做完forward后,我再依次做backward。等把四块GPU上的backward全部做完后,最后一个时刻我统一更新每一层的梯度。这样做确实能训更大的模型了,但也带来了两个问题:如图,阴影部分所表示的时间段里,总有GPU在空转。在Gpipe中,将阴影部分定义为bubble。我们来计算一下bubble。假设有K块GPU,而单块GPU上做一次forward和backward的时间为:那么:•动机:当你有一个单卡装不下的大模型时•解决办法:把模型隔成不同的层,每一层都放到一块GPU上,如下图:1.GPU利用度不够•图中灰色长方形的整体面积为:•图中实际在做forward和backward的面积为:则我们定义出bubble部分的时间复杂度为:当K越大,即GPU的数量越多时,空置的比例接近1,即GPU的资源都被浪费掉了。因此这个问题肯定需要解决。在做backward计算梯度的过程中,我们需要用到每一层的中间结果z。假设我们的模型有L层,每一层的宽度为d,则对于每块GPU,不考虑其参数本身的存储,额外的空间复杂度为从这个复杂度可以看出,随着模型的增大,N,L,d三者的增加可能会平滑掉K增加带来的GPU内存收益。因此,这也是需要优化的地方。三、流水线并行(PipelineParallelism)图解?朴素的模...










发表评论取消回复