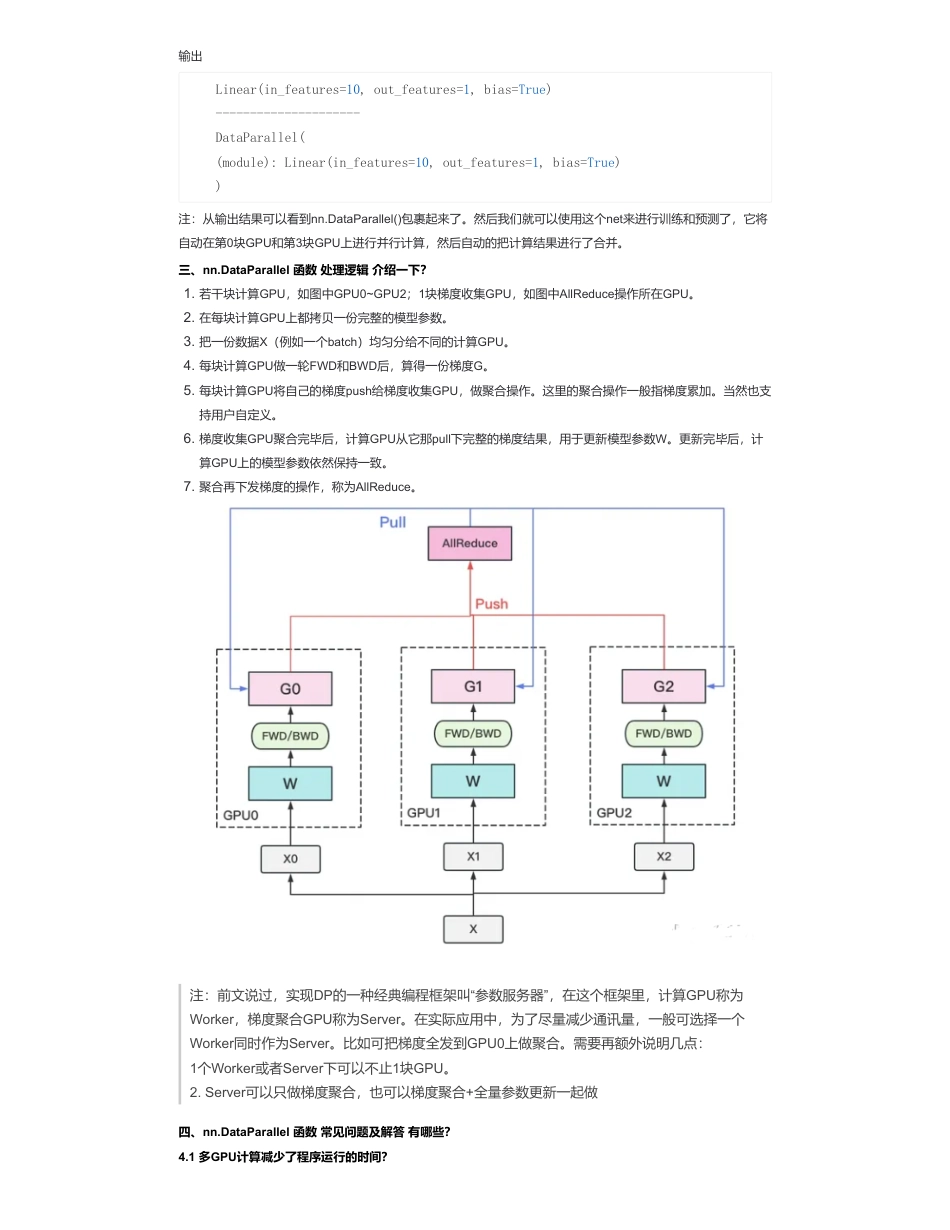
图解分布式训练(二)——nn.DataParallel篇来自:AiGC面试宝典宁静致远2023年09月29日11:14为什么需要nn.DataParallel?多GPU并行训练的原理就是将模型参数和数据分布到多个GPU上,同时利用多个GPU计算加速训练过程。具体实现需要考虑以下两个问题:数据如何划分?因为模型需要处理的数据通常很大,将所有数据放入单个GPU内存中可能会导致内存不足,因此我们需要将数据划分到多个GPU上。一般有两种划分方式:计算如何协同?因为每个GPU都需要计算模型参数的梯度并将其发送给其他GPU,因此需要使用同步机制来保证计算正确性。一般有两种同步方式:一、pytorch中的GPU操作默认是什么样?pytorch中的GPU操作默认是异步的,当调用函数需要使用GPU时,该函数操作就会进入特定设备队列中等待执行,正因为此,pytorch支持并行计算。不过pytorch并行计算的效果对调用者是不可见。Pytorch中的多GPU并行计算是数据级并行,相当于开了多个进程,每个进程自己独立运行,然后再整合在一起。二、介绍一下nn.DataParallel函数?nn.DataParallel函数使用实例•数据并行:将数据分割成多个小批次,每个GPU处理其中的一个小批次,然后将梯度汇总后更新模型参数。•模型并行:将模型分解成多个部分,每个GPU处理其中一个部分,并将处理结果传递给其他GPU以获得最终结果。•数据同步:在每个GPU上计算模型参数的梯度,然后将梯度发送到其他GPU上进行汇总,最终更新模型参数。•模型同步:在每个GPU上计算模型参数的梯度,然后将模型参数广播到其他GPU上进行汇总,最终更新模型参数。device_ids=[0,1]net=torch.nn.DataParallel(net,device_ids=device_ids)torch.nn.DataParallel(module,device_ids=None,output_device=None,dim=0)•函数参数:•module:即模型,此处注意,虽然输入数据被均分到不同gpu上,但每个gpu上都要拷贝一份模型;•device_ids:即参与训练的gpu列表,例如三块卡,device_ids=[0,1,2];•output_device:指定输出gpu,一般省略。在省略的情况下,默认为第一块卡,即索引为0的卡。此处有一个问题,输入计算是被几块卡均分的,但输出loss的计算是由这一张卡独自承担的,这就造成这张卡所承受的计算量要大于其他参与训练的卡。net=torch.nn.Linear(100,1)print(net)print('---------------------')net=torch.nn.DataParallel(net,device_ids=[0,3])print(net)扫码加查看更多输出注:从输出结果可以看到nn.DataParallel()包裹起来了。然后我们就可以使用这个net来进行训练和预测了,它将自动在第0块GPU和第3块GPU上进行并行计算,然后自动的把计算结果进行了合并。三、nn.DataParallel函数处理逻辑介绍一下?注:前文说过,实现DP的一种经典编程框架叫“参数服务器”,在这个框架里,计算GPU称为Worker,梯度聚合GPU称为Server。在实际应用中,为了尽量减少通讯量,一般可选择一个Worker同时作为Server。比如可把梯度全发到GPU0上做聚合。需要再额外说明几点:1个Worker或者Server下可以不止1块GPU。2.Server可以只做梯度聚合,也可以梯度聚合+全量参数更新一起做四、nn.DataParallel函数常见问题及解答有哪些?4.1多GPU计算减少了程序运行的时间?Linear(in_features=10,out_features=1,bias=True)---------------------DataParallel((module):Linear(in_features=10,out_features=1,bias=True))1.若干块计算GPU,如图中GPU0~GPU2;1块梯度收集GPU,如图中AllReduce操作所在GPU。2.在每块计算GPU上都拷贝一份完整的模型参数。3.把一份数据X(例如一个batch)均匀分给不同的计算GPU。4.每块计算GPU做一轮FWD和BWD后,算得一份梯度G。5.每块计算GPU将自己的梯度push给梯度收集GPU,做聚合操作。这里的聚合操作一般指梯度累加。当然也支持用户自定义。6.梯度收集GPU聚合完毕后,计算GPU从它那pull下完整的梯度结果,用于更新模型参数W。更新完毕后,计算GPU上的模型参数依然保持一致。7.聚合再下发梯度的操作,称为AllReduce。虽然使用nn.DataParallel函数能够进行多GPU运算,但是会导致程序花费的时间不减反增,这是为什么呢?在第三节提到,nn.DataParallel函数会将每个batch数据...










发表评论取消回复