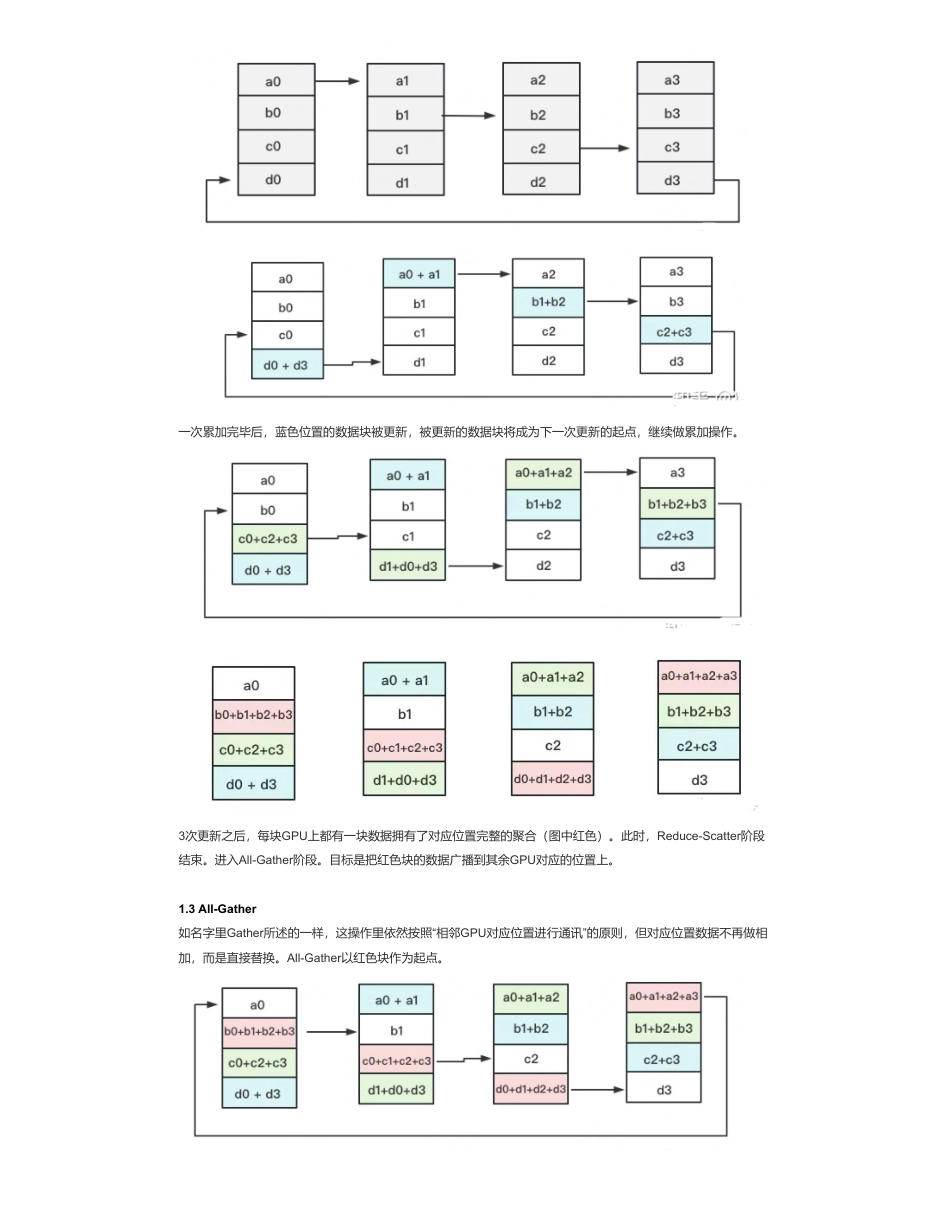
图解分布式训练(三)——nn.parallel.DistributedDataParallel来自:AiGC面试宝典宁静致远2023年09月29日11:22为什么需要nn.parallel.DistributedDataParallel?多GPU并行训练的原理就是将模型参数和数据分布到多个GPU上,同时利用多个GPU计算加速训练过程。具体实现需要考虑以下三个问题:一、什么是DistributedDataParallel核心——Ring-AllReduce?上节讲到DP只支持单机多卡场景,主要原因是DP无法数据并行中通讯负载不均的问题,而DDP能够解决该问题的核心在于Ring-AllReduce。它由百度最先提出,非常有效地解决了数据并行中通讯负载不均的问题,使得DDP得以实现。1.1Ring-AllReduce介绍假设有4块GPU,每块GPU上的数据也对应被切成4份。AllReduce的最终目标,就是让每块GPU上的数据都变成箭头右边汇总的样子。Ring-ALLReduce则分两大步骤实现该目标:Reduce-Scatter和All-Gather。1.2Reduce-Scatter然后你对该问题一丝不解,没事,下文将用图例把详细步骤介绍清楚。1.**数据如何划分?**因为模型需要处理的数据通常很大,将所有数据放入单个GPU内存中可能会导致内存不足,因此我们需要将数据划分到多个GPU上。一般有两种划分方式:•数据并行:将数据分割成多个小批次,每个GPU处理其中的一个小批次,然后将梯度汇总后更新模型参数。•模型并行:将模型分解成多个部分,每个GPU处理其中一个部分,并将处理结果传递给其他GPU以获得最终结果。2.**计算如何协同?**因为每个GPU都需要计算模型参数的梯度并将其发送给其他GPU,因此需要使用同步机制来保证计算正确性。一般有两种同步方式:•数据同步:在每个GPU上计算模型参数的梯度,然后将梯度发送到其他GPU上进行汇总,最终更新模型参数。•模型同步:在每个GPU上计算模型参数的梯度,然后将模型参数广播到其他GPU上进行汇总,最终更新模型参数。3.DP只支持单机多卡场景,在多机多卡场景下,DP的通讯问题将被放大。•DDP首先要解决的就是通讯问题:将Server上的通讯压力均衡转到各个Worker上。实现这一点后,可以进一步去Server,留Worker。•介绍:定义网络拓扑关系,使得每个GPU只和其相邻的两块GPU通讯。每次发送对应位置的数据进行累加。每一次累加更新都形成一个拓扑环,因此被称为Ring。扫码加查看更多一次累加完毕后,蓝色位置的数据块被更新,被更新的数据块将成为下一次更新的起点,继续做累加操作。3次更新之后,每块GPU上都有一块数据拥有了对应位置完整的聚合(图中红色)。此时,Reduce-Scatter阶段结束。进入All-Gather阶段。目标是把红色块的数据广播到其余GPU对应的位置上。1.3All-Gather如名字里Gather所述的一样,这操作里依然按照“相邻GPU对应位置进行通讯”的原则,但对应位置数据不再做相加,而是直接替换。All-Gather以红色块作为起点。以此类推,同样经过3轮迭代后,使得每块GPU上都汇总到了完整的数据,变成如下形式:二、nn.parallel.DistributedDataParallel函数介绍一下?nn.parallel.DistributedDataParallel函数三、nn.parallel.DistributedDataParallel函数如何多卡加速训练?DDP在各进程梯度计算完成之,各进程需要将梯度进行汇总平均;然后再由rank=0的进程,将其broadcast到所有进程后,各进程用该梯度来独立的更新参数,而DP是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余的GPU。由于DDP各进程中的模型,初始参数一致(初始时刻进行一次broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个optimizer,对各个GPU上梯度进行求,而在主卡进行参数更新,之后再将模型参数broadcast到其他GPU四、nn.parallel.DistributedDataParallel实现流程介绍一下?CLASStorch.nn.parallel.DistributedDataParallel(module,device_ids=None,output_device=None,dim=0,broadcast_buffers=True,process_group=None,bucket_cap_mb=25,find_unused_parameters=False,check_reduction=False)•函数参数•module是要放到多卡训练的模型;•device_ids数据类型是一个列表,表示可用的gpu卡号;•output_devices数据类型也是列表,表示模型输出结果存放的卡号(如果...










发表评论取消回复