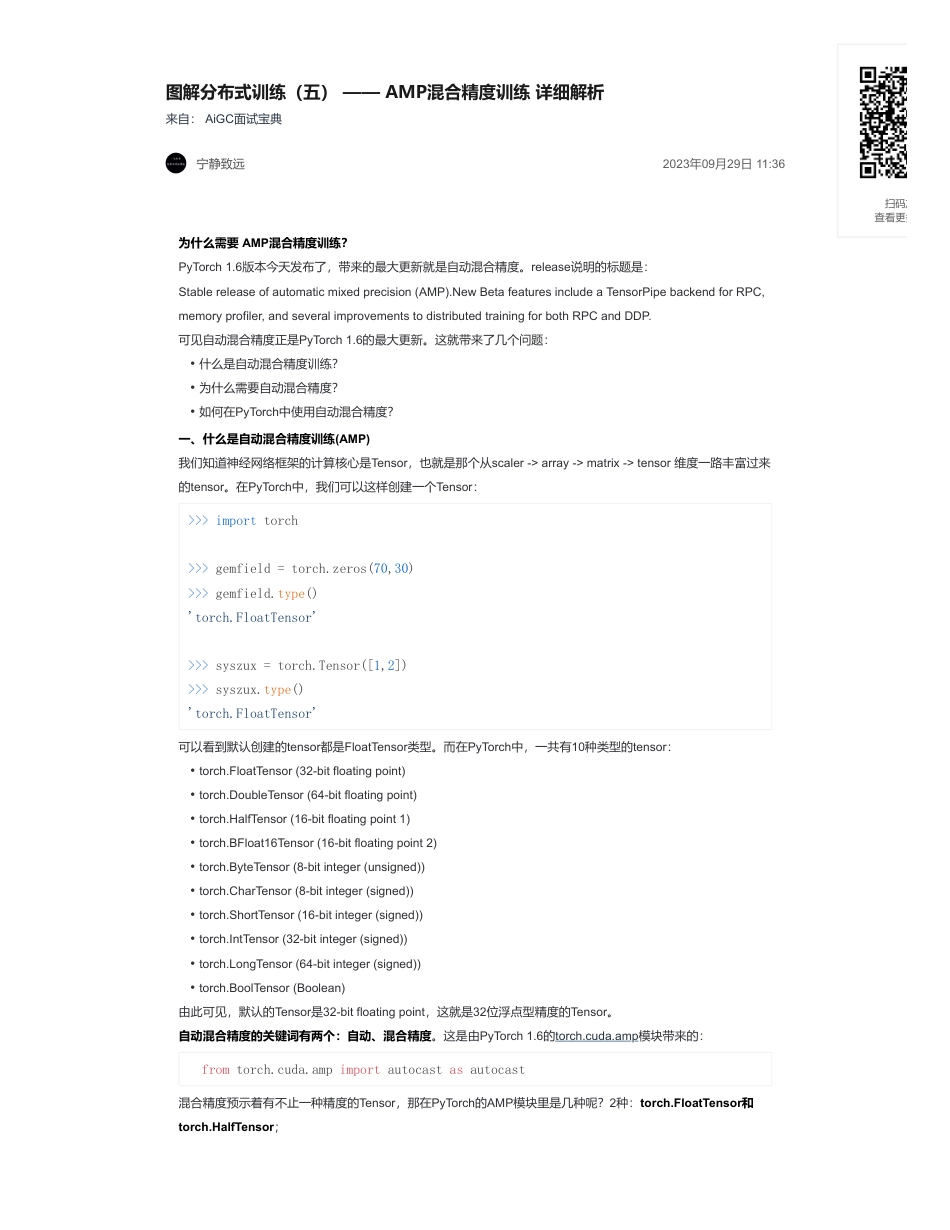
图解分布式训练(五)——AMP混合精度训练详细解析来自:AiGC面试宝典宁静致远2023年09月29日11:36为什么需要AMP混合精度训练?PyTorch1.6版本今天发布了,带来的最大更新就是自动混合精度。release说明的标题是:Stablereleaseofautomaticmixedprecision(AMP).NewBetafeaturesincludeaTensorPipebackendforRPC,memoryprofiler,andseveralimprovementstodistributedtrainingforbothRPCandDDP.可见自动混合精度正是PyTorch1.6的最大更新。这就带来了几个问题:一、什么是自动混合精度训练(AMP)我们知道神经网络框架的计算核心是Tensor,也就是那个从scaler->array->matrix->tensor维度一路丰富过来的tensor。在PyTorch中,我们可以这样创建一个Tensor:可以看到默认创建的tensor都是FloatTensor类型。而在PyTorch中,一共有10种类型的tensor:由此可见,默认的Tensor是32-bitfloatingpoint,这就是32位浮点型精度的Tensor。自动混合精度的关键词有两个:自动、混合精度。这是由PyTorch1.6的torch.cuda.amp模块带来的:混合精度预示着有不止一种精度的Tensor,那在PyTorch的AMP模块里是几种呢?2种:torch.FloatTensor和torch.HalfTensor;•什么是自动混合精度训练?•为什么需要自动混合精度?•如何在PyTorch中使用自动混合精度?>>>importtorch>>>gemfield=torch.zeros(70,30)>>>gemfield.type()'torch.FloatTensor'>>>syszux=torch.Tensor([1,2])>>>syszux.type()'torch.FloatTensor'•torch.FloatTensor(32-bitfloatingpoint)•torch.DoubleTensor(64-bitfloatingpoint)•torch.HalfTensor(16-bitfloatingpoint1)•torch.BFloat16Tensor(16-bitfloatingpoint2)•torch.ByteTensor(8-bitinteger(unsigned))•torch.CharTensor(8-bitinteger(signed))•torch.ShortTensor(16-bitinteger(signed))•torch.IntTensor(32-bitinteger(signed))•torch.LongTensor(64-bitinteger(signed))•torch.BoolTensor(Boolean)fromtorch.cuda.ampimportautocastasautocast扫码加查看更多自动预示着Tensor的dtype类型会自动变化,也就是框架按需自动调整tensor的dtype(其实不是完全自动,有些地方还是需要手工干预);torch.cuda.amp的名字意味着这个功能只能在cuda上使用,事实上,这个功能正是NVIDIA的开发人员贡献到PyTorch项目中的。而只有支持Tensorcore的CUDA硬件才能享受到AMP的好处(比如2080ti显卡)。TensorCore是一种矩阵乘累加的计算单元,每个TensorCore每个时钟执行64个浮点混合精度操作(FP16矩阵相乘和FP32累加),英伟达宣称使用TensorCore进行矩阵运算可以轻易的提速,同时降低一半的显存访问和存储。因此,在PyTorch中,当我们提到自动混合精度训练,我们说的就是在NVIDIA的支持Tensorcore的CUDA设备上使用torch.cuda.amp.autocast(以及torch.cuda.amp.GradScaler)来进行训练。咦?为什么还要有torch.cuda.amp.GradScaler?二、为什么需要自动混合精度?这个问题其实暗含着这样的意思:为什么需要自动混合精度,也就是torch.FloatTensor和torch.HalfTensor的混合,而不全是torch.FloatTensor?或者全是torch.HalfTensor?如果非要以这种方式问,那么答案只能是,在某些上下文中torch.FloatTensor有优势,在某些上下文中torch.HalfTensor有优势呗。答案进一步可以转化为,相比于之前的默认的torch.FloatTensor,torch.HalfTensor有时具有优势,有时劣势不可忽视。torch.HalfTensor的优势就是存储小、计算快、更好的利用CUDA设备的TensorCore。因此训练的时候可以减少显存的占用(可以增加batchsize了),同时训练速度更快;torch.HalfTensor的劣势就是:数值范围小(更容易Overflow/Underflow)、舍入误差(RoundingError,导致一些微小的梯度信息达不到16bit精度的最低分辨率,从而丢失)。可见,当有优势的时候就用torch.HalfTensor,而为了消除torch.HalfTensor的劣势,我们带来了两种解决方案:1.梯度scale,这正是上一小节中提到的torch.cuda.amp.GradScaler,通过放大loss的值来防止梯度的underflow(这只是BP的时候传递梯度信息使用,真正更新权重的时候还是要把放...









发表评论取消回复