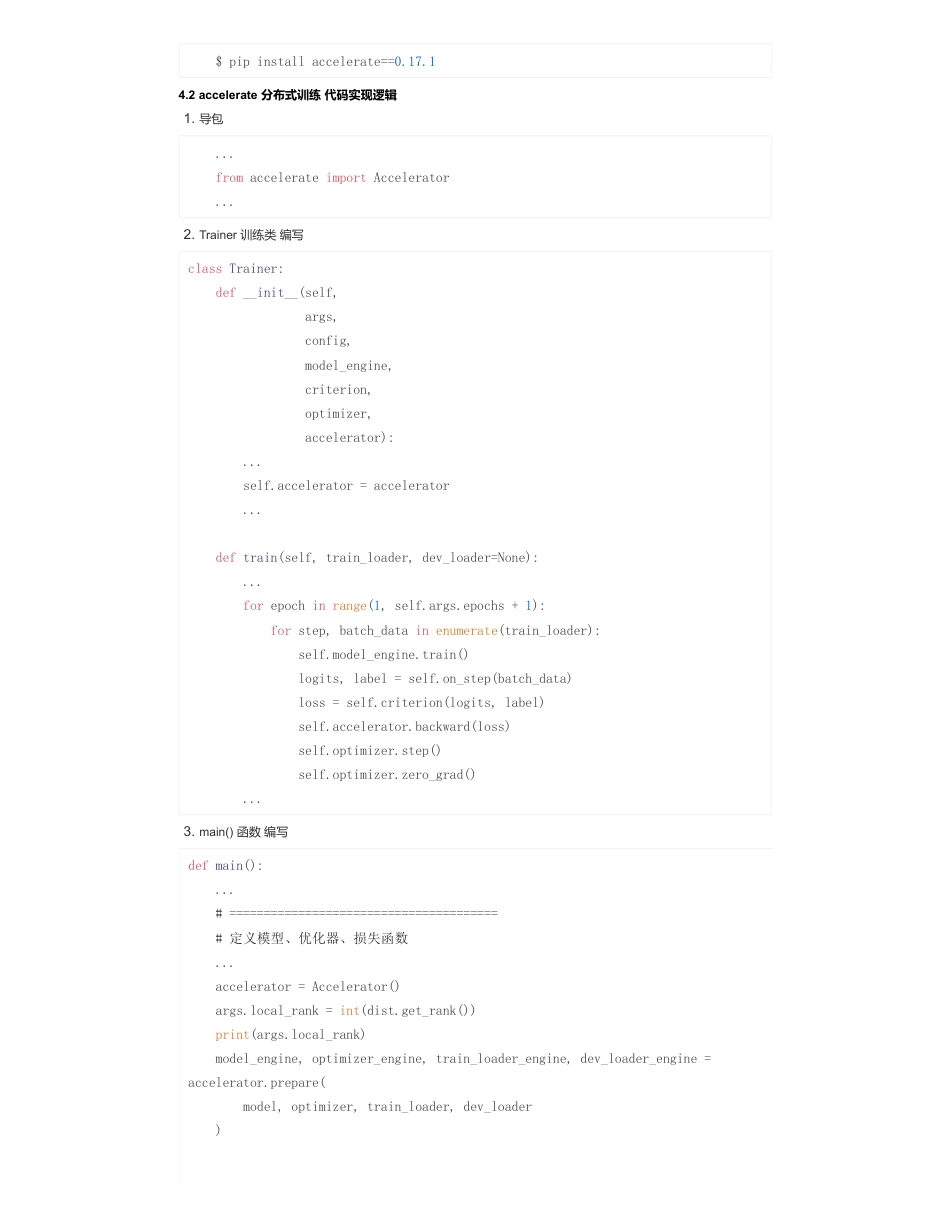
图解分布式训练(七)——accelerate分布式训练详细解析来自:AiGC面试宝典宁静致远2023年09月29日11:58一、为什么需要accelerate分布式训练?PyTorchAccelerate是一个PyTorch的加速工具包,旨在简化PyTorch训练和推断的开发过程,并提高性能。它是由HuggingFace、NVIDIA、AWS和Microsoft等公司联合开发的,是一个开源项目。二、什么是accelerate分布式训练?2.1accelerate分布式训练介绍PyTorchAccelerate提供了一组简单易用的API,帮助开发者实现模型的分布式训练、混合精度训练、自动调参、数据加载优化和模型优化等功能。它还集成了PyTorchLightning和TorchElastic,使用户能够轻松地实现高性能和高可扩展性的模型训练和推断。2.2accelerate分布式训练主要优势PyTorchAccelerate的主要优势包括:三、accelerate分布式训练原理讲解?3.1分布式训练分布式训练是指将一个大型深度学习模型拆分成多个小模型,在不同的计算机上并行训练,最后将结果合并,得到最终的模型。分布式训练可以显著减少模型训练的时间,因为它充分利用了多个计算机的计算资源。同时,由于每个小模型只需要处理部分数据,因此可以使用更大的批次大小,进一步提高训练速度。3.2加速策略Accelerate提供了多种加速策略,如pipeline并行、数据并行等。3.2.1Pipeline并行Pipeline并行是指将模型拆分成多个部分,在不同的计算机上并行训练。在每个计算机上,只需要处理模型的一部分,然后将结果传递给下一个计算机。这样可以充分利用多个计算机的计算资源,并且可以使用更大的批次大小,提高训练速度。Pipeline并行的缺点是,由于每个计算机只处理部分数据,因此每个计算机的结果都会有一些误差,最终的结果可能会有一些偏差。3.2.2数据并行数据并行是指将数据拆分成多个部分,在不同的计算机上并行训练。在每个计算机上,都会处理全部的模型,但是每个计算机只处理部分数据。这样可以充分利用多个计算机的计算资源,并且可以使用更大的批次大小,提高训练速度。数据并行的优点是,每个计算机都会处理全部的模型,因此结果更加准确。缺点是,由于每个计算机都需要完整的模型,因此需要更多的计算资源。3.2.3加速器加速器是指用于加速深度学习模型训练的硬件设备,如GPU、TPU等。加速器可以大幅提高模型的训练速度,因为它们可以在更短的时间内完成更多的计算。Accelerate可以自动检测并利用可用的加速器,以进一步提高训练速度。四、accelerate分布式训练如何实践?4.1accelerate分布式训练依赖安装•分布式训练:可以在多个GPU或多台机器上并行训练模型,从而缩短训练时间和提高模型性能;•混合精度训练:可以使用半精度浮点数加速模型训练,从而减少GPU内存使用和提高训练速度;•自动调参:可以使用PyTorchLightningTrainer来自动调整超参数,从而提高模型性能;•数据加载优化:可以使用DataLoader和DataLoaderTransforms来优化数据加载速度,从而减少训练时间;•模型优化:可以使用Apex或TorchScript等工具来优化模型性能。扫码加查看更多4.2accelerate分布式训练代码实现逻辑$pipinstallaccelerate==0.17.11.导包...fromaccelerateimportAccelerator...2.Trainer训练类编写classTrainer:def__init__(self,args,config,model_engine,criterion,optimizer,accelerator):...self.accelerator=accelerator...deftrain(self,train_loader,dev_loader=None):...forepochinrange(1,self.args.epochs+1):forstep,batch_datainenumerate(train_loader):self.model_engine.train()logits,label=self.on_step(batch_data)loss=self.criterion(logits,label)self.accelerator.backward(loss)self.optimizer.step()self.optimizer.zero_grad()...3.main()函数编写defmain():...#=======================================#定义模型、优化器、损失函数...accelerator=Accelerator()args.local_rank=int(dist.get_rank())print(args.local_rank)model_engine,optimizer_engine,train_loader_engine,dev_loader_engine=accelerator.prepare(model,optimizer,train_loader,dev_loader)4.3accelerate分布式训练示例代码#======...










发表评论取消回复